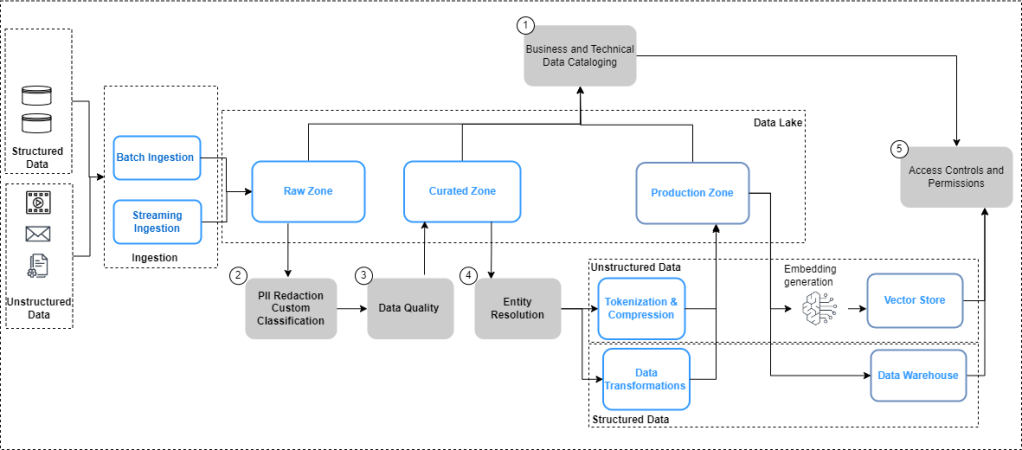
There is a lot of talk about a data strategy for Generative AI. And rightfully so – as companies will continue to find out ways to leverage enterprise data assets to better ground the Foundation Models (FMs). Earlier this year, I and a couple of my colleagues had written a blogpost on data governance for Generative AI. As part of that, we had laid down a data management blueprint for enabling Generative AI (see below). This was designed with the first wave of domain adaptation of the FMs for enterprise use-cases has by and large, been led by RAG (Retrieval Augmented Generation).
A few months seems like a whole new generation in the AI world. As I mentioned in last week’s post, the falling costs/token and the plateauing of models is shifting the focus even more sharply to data for deeper domain adaptation of FMs. One such pattern that we are beginning to see is continued pre-training (CPT). In this, there is an ongoing training of FMs (i.e. refining model weights) using unsupervised data. While fine-tuning is essential for tailoring models with enterprise specific style and content guidelines for specific tasks like summarization, Q&A etc., CPT grounds the LLMs with deeper domain knowledge (e.g. finance, law) specific to the industry (e.g. healthcare) or function (e.g. Procurement). This series of articles gives an excellent primer on this topic. CPT requires vast corpora of private training data ranging from static (e.g. product manuals) to data that is changing (e.g. emails, customer chat transcripts etc.), with the latter being critical to keep the model contextually relevant with ever changing domain knowledge. Here’s the catch: CPT is resource intensive (and hence expensive) and despite the falling costs, CPT costs can quickly add-up, especially if it has to be done on an ongoing basis.
There is some evidence that data quality can be used to improve model performance (in the context of vision pre-training). Can we extend the idea to develop some governing principles for creating high-quality datasets for CPT? Turns out that some of the same principles that we have been using for Feature Engineering as part of ML data engineering might be applicable here as well:
- Coverage Sampling: The goal should be to maximize coverage by selecting data that is distributed across the entire input domain. The motivation is that we should be using the full breadth of topics at hand. One way to accomplish this is to use clustering techniques like the tried and tested k-means sampling. You could explore different variants of this strategy – for instance, remove points which fall too close to the k-means centroid for the high density clusters
- Quality-score Sampling: This is the notion of developing a quality score using an algorithm to rate each element in the training dataset and use the high-quality samples. For instance, in case of customer chat transcripts, it might make sense to define a quality score for each conversation unit based on a pre-defined set of business criteria (e.g. length of conversation, resolution status etc.) and use that as a filter criteria for selecting high-quality samples.
- Density Sampling: It is a well understand phenomenon that the data distribution provides a strong coverage signal. High-probability regions (i.e. dense clusters) will contain prototypical examples, with strong representation in the dataset. Meanwhile, low-probability regions (i.e. sparse clusters) will contain outliers, noise, and/or unique inputs. If the strategy is to get the GenAI to perform better with outlier scenarios, it would be a good idea to boost the signal from the under-represented portions of the input domain and down-sample redundant high-density information.
These are just a few methods that can be used as part of your sampling strategy to create high-quality, limited datasets for CPT jobs. The main point is this: A robust sampling strategy is a necessary toolkit as part of the data pipelines for unstructured data needs to be added to what we laid out in Figure 1. Building effective and efficient training datasets for continued pre-training of Foundation Models will continue to grow in importance with the continuing need in the domain adaptation of LLMs to support deep domain, enterprise-specific GenAI use-cases.
Further reading: How to train data-efficient LLMs

Leave a comment