In 1651, Thomas Hobbes wrote, “reason … is nothing but reckoning (that is, Adding and Subtracting) of the Consequences of generall names agreed upon.” It is widely accepted that with this, he laid the foundation for the Computational theory of the mind. And as often happens in science, one thing led to the other and 300 years later, AI is having a go at this very idea: attempting to replicate the human brain as a computational machine. I don’t want to wade into the philosophical arguments of this – my goal is far more prosaic: how might we be able to learn from the human information processing architecture to design a learning architecture in an enterprise?
Let’s start with abstracting how we think for a certain class of problems: navigating the world by responding to external signals. Here’s an oversimplified computational theory of the brain:
- Absorb the signals: We are inundated with information all the time – we have a way of filtering out what the necessary signals are and ignore the noise (it is uncanny – we are constantly applying the Occam’s razor) If we have to remember a route, we don’t bother with every minute detail – we have a mechanism to focus on the major landmarks just enough to get us through and file them away.
- Process the information: Once we gather up the signals, we are particularly good at pattern matching based on our inbuilt classification system. And if it turns out to be a uniquely different situation, we create a new branch in our tree and file it away. Once we have a reference frame, our mental processor evaluates the signal against expectation. This is obviously not sequential, but goes back and forth with step-1. And in (very) short order, we have a decision to make: does this situation deviate enough from the expectation to warrant a response?
- Figure out how to respond: We weigh the odds of different responses – and go with our best choice as the decision. This is could be an ‘instinctive’ response, drawn from past experiences and/or training. Or it could be a ‘thoughtful’ response, driven by a logical framework of rules. This is our very own risk-weighted choice engine at play (Daniel Kahnemann’s Thinking Fast, Slow for more)
- Learn and adapt: Once we act the decision out, we wait for the next set of signals, i.e. the feedback loop. What makes us uniquely different as a species is our ability to abstract from learning at an individual level to broad frameworks of rules. And these are rules not just our individual ones, but we can share, codify and collectively build this framework of rules

And this is basically the process by which each one of us interfaces with the world, undergoes experiences and continuously learn as an individual and collectively as a species from the minute we are born. Of course, there is the whole thing about WHY we act in the first place: we often initiate action driven by intrinsic motivation that is not always physical or instinctive (e.g. the desire for power vs. desire for food to satisfy hunger as a biological trigger). Let’s set that aside for the moment.
And so back to the question: can we think of a generic AI architecture for the enterprise that can be inspired by the human brain? This enterprise AI ‘brain’ will necessarily be triggered into an action by one of the three scenarios:
- External impetus: the environment, customers, suppliers, employees etc. exhibit a change in behavior (e.g. Competitor announces a new service line; your product is going off-patent)
- Objective: To drive a business goal, there is an objective that needs to be achieved (e.g. increase digital sales by x% as part of the enterprise digital strategy)
- Question: The ‘water-cooler trigger’ (someone asks a ‘what-if’ question) or the ‘pesky boss trigger’ (why is something happening)
The specifics of such a system will of course be determined by the intent (i.e. the business problem that needs to be solved) – what we want to do here is to describe the 4 building blocks and think of the classes of algorithms in each building block:
- Input processor: Traditionally, you would start with good old-fashioned hypothesis testing to narrow down the variables that are significant to the problem at hand. A class of algorithms – Principal Component Analysis (PCA) is especially useful to narrow down focus on the relevant features in a dataset of input signals.
- Process the information: The response is broadly determined in one of two ways:
- How does the observation match up against the expectation: In other words, forecast the value and then assess whether the actual is an anomaly. A whole class of Anomaly Detection algorithms can be pressed into service: start with a forecasting algorithm (supervised and where possible, unsupervised) and then determine whether the actual observation is an Anomaly based on a set of rules
- How does the observation compare to the known set of historical observations? Clustering algorithms have been around for a while now, and extremely useful as an unsupervised method of grouping all historical observations and use that as a reference to assess if the current observation is an Anomaly
- Next Best Action: Recommender algorithms can then fire up and suggest an action that works at a cluster level. It was not too long ago that recommendation algorithms were what I call ‘what’ driven: predict the next best action based on a set of factors (supervised). Of late, the focus is shifting to ‘who’ driven: predict the next best action based on the revealed preferences of others in the cluster (unsupervised)
- Exploring by doing (aka experimentation): Once the decision is executed, the important thing is to make sure you are learning from it. Instrumentation is key – make sure that the action has a well-defined measurement mechanism. Does the customer accept the offer? Alternatively, where possible – define a portfolio of offers and experiment with your customer base to find out which one works best).
- Observation and learning: And finally the most important element: what does it mean to actually learn? Was this the right NBA? If yes, should the ‘input to output’ sequence be rewarded? And conversely, if this was not the right NBA, should this sequence be penalized? What if we let the algorithm learn over time and let it keep getting better? Say hello to Reinforcement Learning
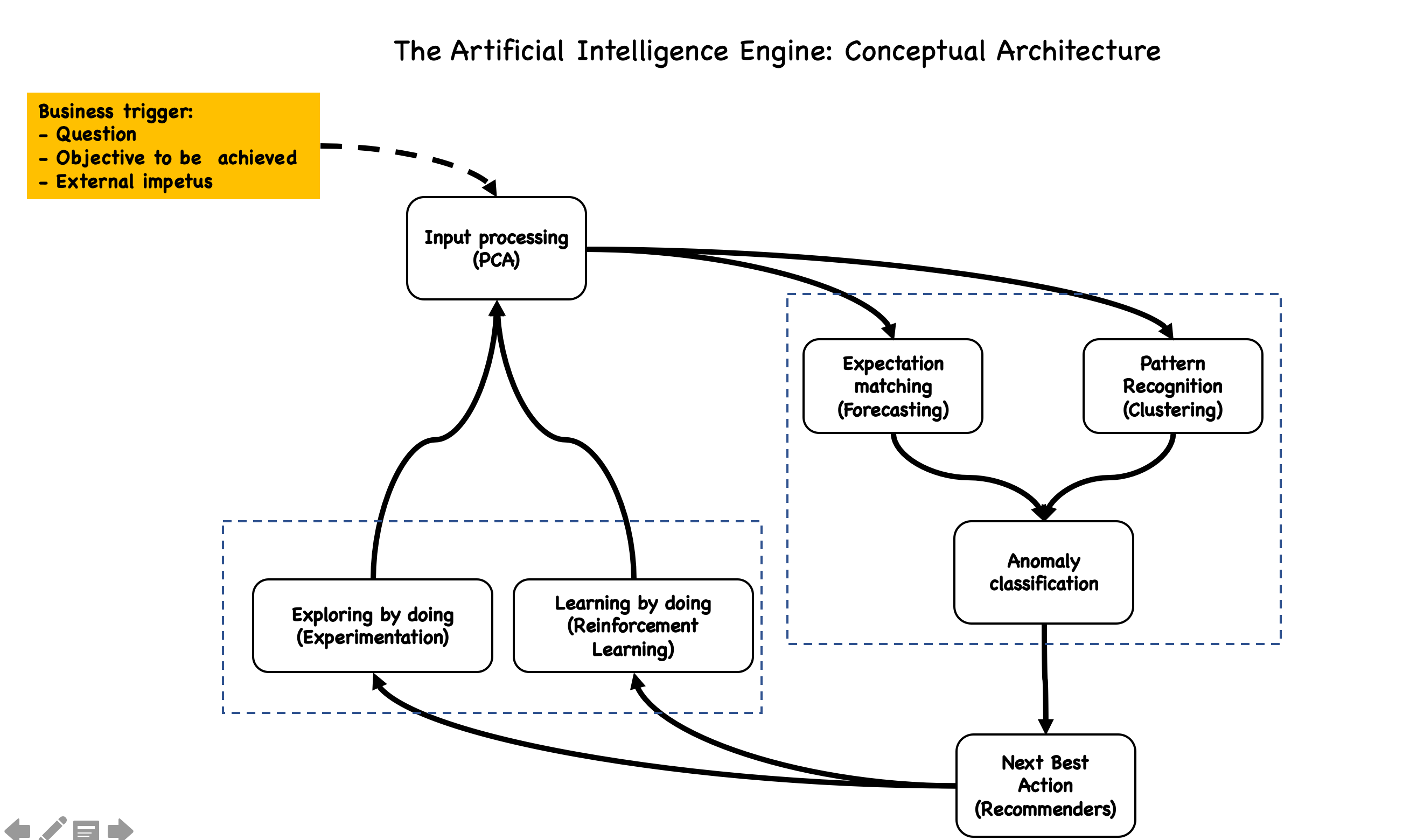
And so, we have a generalized learning system architecture. Depending on the problem space, data quality and availability, the actual implementation algorithms will vary – a good place to start would be to build this as a ‘learning engine pipeline’. Over time, the algorithms will be the re-usable modules that can help accelerate the time to decision for every new problem category,
Footnote: I am reading a fascinating book: “Range: Why generalists triumph in a specialized world” by David Epstein. Research has shown that two of the most effective learning strategies are: 1) start with fewer rules and evolve the learning by doing. As opposed to received wisdom built from past experiences 2) Breadth of training is a great predictor of transfer. Learners who are exposed a wide variety of situations tend to perform better in new situations. Our Learning System must allow for both – the journey from supervised to unsupervised learning systems; rapid deployment so that the true learning can happen by ‘reinforcement’ in a real-life context.

Leave a comment