Some of you reached out to ask me how the idea of Natural Experiments is any different from the standard experiments (test/control, A/B testing et al). The latter (let’s call them Controlled experiments) differ in two critically important ways:
- Controlled experiments have the ability to define the relevant populations upfront. This is a huge advantage – and crucially, helps in arriving at the causality or association (more on this further down) with reasonable confidence.
- Controlled experiments can be designed and executed in a way that minimizes the effect of external factors. This, coupled with the increasingly sophisticated Machine Learning algorithms, makes a big difference in improving the accuracy of the causality or association.
You will want to think about Natural Experiments when you don’t have the luxury of either of the above. Needless to say, that creates the burden of analyzing the data in a way that makes these experiments reliable. I do think though that natural experiments are better at establishing association (or correlation) than causation.
A quick side-bar on the difference between correlation and causation. After all, ‘Correlation is not Causation’ is a t-shirt worthy phrase in the data world. And yet, I am often surprised how loosely this is used. Here’s an attempt to formalize this – I think it is important to get this right – especially if you have anything to do with trying to use data for decision making.
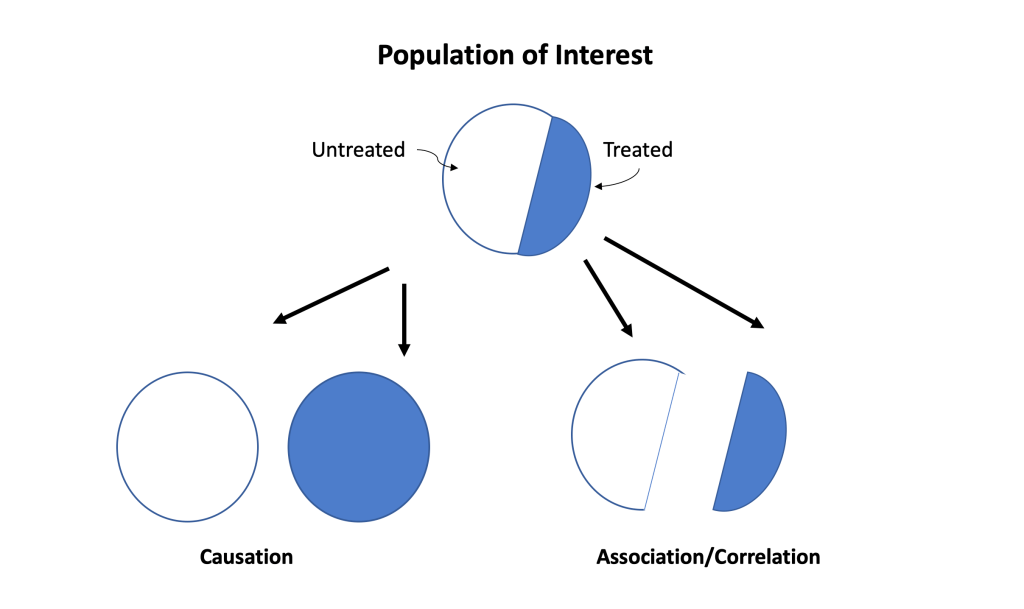
Causation: is an attempt to understand the difference in outcomes if the entire population is treated (blue) or not treated at all (white). In other words, we attempt to answer the ‘what-if’ question (remember counterfactuals): “What is the risk (probability of an outcome) if everyone is treated?” and“What is the risk if nobody is treated?”
Correlation/Association: is an attempt to understand questions in the ‘real world’. In other words, the goal is to understand “What is the risk in the treated?” vs. “What is the risk in the untreated?” The critical thing to remember is that correlation is defined by the different risks in disjointed populations determined by the treatment (blue and white) whereas causation is defined by the different risks in the same population under two different treatments.
So what?
Like I mentioned last week, ‘Cause and effect’ is having a moment – and it is not just the Economics Nobel prizes this year. The Economist this week headlined the emerging trend of ‘Instant Economics’ – definitely worth a read. It has a catchy phrase – ‘Vast and Fast data’, which aptly summarizes what is going on around us today. Consumer data explosion has been going on for several years now – Enterprise data is catching up rapidly. And even more importantly, data is becoming richer every day: it is not just social media or clickstream data, but data from sensors (e.g. real-time updates from manufacturing sites), mobile assets (e.g. supply chain inventory positions in real-time), financial flows (e.g. digital payments). Case in point: 3 professors from Northwestern, Stanford and University of Chicago have developed a series of ‘Uncertainty’ indices based on real-time data (e.g newspaper reports, Twitter etc.). The idea here is not just rely from very slow, lagging indices (like GDP growth rates, unemployment rates etc.) which capture the economic picture far too late and move towards leading indicators. And as that happens, the ‘cause-and-effect’ argument is also shifting from causation to correlation, which is a big deal in the macroeconomic policy world.
And that is the opportunity with Enterprises as well: instead of getting caught up in the ‘causation vs. correlation’ debate, exploit the ‘vast and fast’ troves of data for better, timelier and rational decision-making. Time to update the t-shirt slogan: ‘Causation vs and Correlation’
Further reading:
Economist article: https://www.economist.com/briefing/2021/10/23/enter-third-wave-economics
Uncertainty Indices: https://www.policyuncertainty.com/index.html
