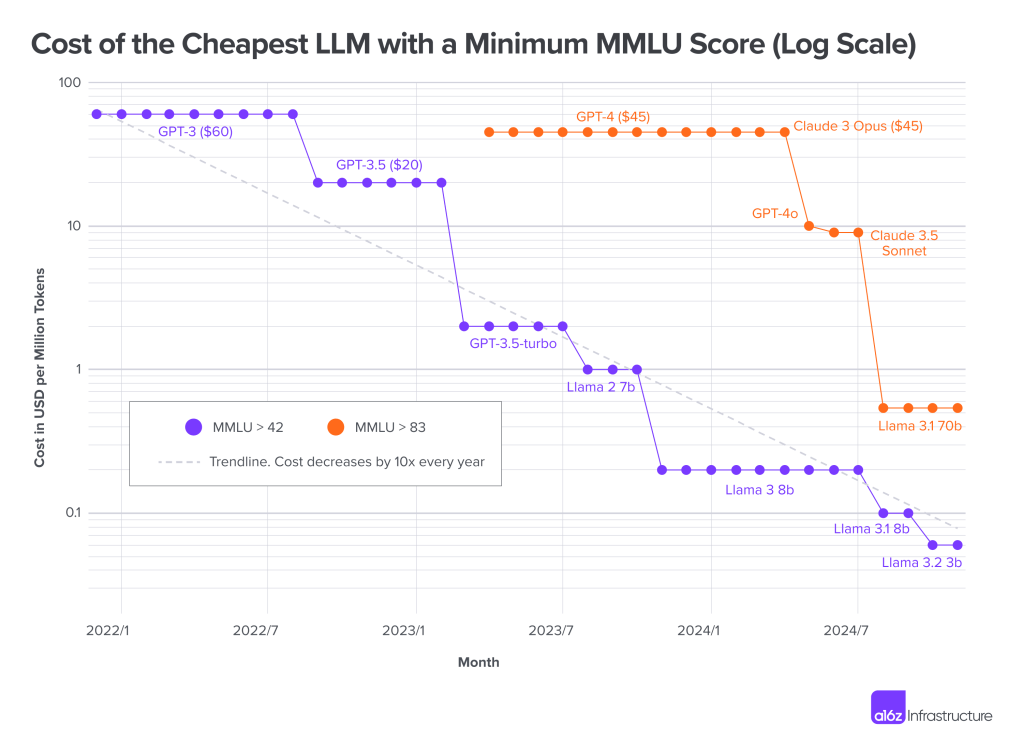
The Scaling Laws have formed the basis for the development efforts of the various companies building Foundation Models. Simplistically put, the models get better with model size, dataset size, and the amount of compute used for training, and by and large, this has held across all the FMs. After the astonishingly rapid development in the last 2 years, there are two clear patterns emerging. Firstly, Transformer models seem to have hit a ceiling and the open-source (actually open-weight) models are catching up with the proprietary ones (see Figure 1). Researchers point to insufficient high-quality training data as one possible reason for the slowdown. This is also motivating the model providers to enhance the reasoning capabilities. This is essentially shifting focus from pre-training to inference by allocating computing capacity to task completion. AI agents that can reason with the capability to plan, interact with their environment and iterate to achieve a goal are becoming increasingly real. This opens up huge possibilities for enterprise AI adoption. At the same time, the LLM costs continue to drop (see Figure 2).

So, what does this mean to Enterprise AI adoption? I think we are getting really started now to fuel business transformation with AI. Here are three things that I expect we will see in the coming months:
1/ Proliferation of use-cases: With the falling LLM costs, the cost of deploying some of the use-cases continues to drop, to a point where it is becoming economically viable to deploy many use-cases across functions. For instance, simple task automation activities like document summarization, conversational search interfaces, text-to-speed based voice-assistants et al are becoming easier to fund, and we should expect to see a proliferation of these use-cases. And to do that, I would expect enterprises to build platforms that offer capabilities (e.g. choice of LLMs, knowledge bases, governance) to enable teams and even individuals to build and deploy these ‘virtual assistants’. We are already seeing signs of these assistants taking on sophisticated tasks. In one case, the legal function is using a ‘legal contract chatbot’ that compares contract versions and tracks changes, flags potential contract violations and so on. The clear and obvious factor here is to arm the LLMs with the ability to leverage enterprise data, both structured and unstructured. There is much work to be done here – e.g. one big area of interest is natural language query interfaces. LLM-based text2sql systems are getting a lot of traction, with accuracy being the main barrier to adoption (more on that later).
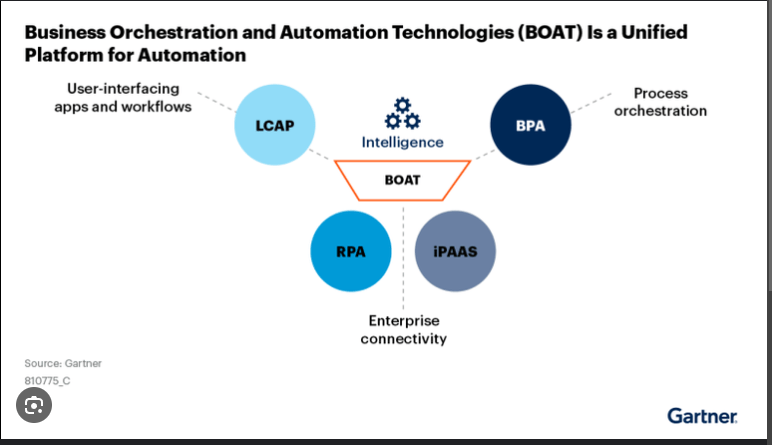
2/Agentic AI Systems: The shift in focus to improving inference capabilities with ‘Agentic AI’ is making it possible to truly re-engineer business processes. The traditional RPA (Robotic Process Automation) software required deterministic flows, which meant that RPA would throw an exception whenever a scenario that was not pre-programmed presented itself. And in a world where exceptions are becoming more common (fat-tail distributions is a favorite topic of mine – will come back to this next week!), Agentic AI presents the possibility of being given an outcome goal (e.g. a target SLA), a set of resources (data), and left to plan and execute the necessary tasks. There is obviously lots more to this, but we are already seeing examples of Agents in use. In the legal contract chatbot example, the AI Agent ‘evaluates’ procurement contracts to identify possible exceptions – for instance, invoking the forecast and assessing the probability of shifting to a different price tier and using that to alert a potential remediation action to the buyers. It is early days yet, but the prospects are tremendous. We can expect to see a huge surge in the adoption of ‘AI as a Service’, or as Gartner (see Figure 3) is calling this new capability: ‘BOAT’ (Business Orchestration and Automation Technologies)
Data is the differentiator
Building Agentic systems that will meaningfully solve a business problem or improve a process and drive greater efficiency will require deep context which is where data comes in. It is becoming clear that data will have two critical roles to play:
- Most, if not all, of the Agentic systems will have to make execution choices based on data. Some of this data will be in-context, which is where capabilities like Anthropic’s computer use will be useful. A bigger source will be mining intelligence from transaction system data, which will require robust data pipelines that ingest the data from transaction systems and provide access to the data through APIs that the Agents can invoke as part of the workflows. And increasingly, this will be a combination of structured and unstructured data.
- The LLMs invoked by the Agentic systems themselves need to be grounded in enterprise context. While the first wave of use-cases were driven by RAG, we should expect fine-tuning and even continued pre-training of Foundation models. Some of the industry leaders are already well underway in developing domain-specific LLMs. We should expect an increase in this with the rise of the open-source models and falling inference costs.
Any progress on deploying Agentic systems will be heavily predicated by the Data strategy – from accessing data generated from transaction systems and landing them in a Data Lake, driving the necessary data transformations, and finally, a strong governance that allows for the right access for individual Agentic systems, even as enforcing the enterprise security and policy guardrails. We should expect to see the notion of governance to expand and holistically cover AI and Data with the same set of security policies and guardrails.
In the coming weeks, I will dive deep into two major areas of interest:
- Deeper understanding of data and one of my favorite topics: the over-simplifying assumptions of Gaussian distributions where as real-life phenomena seem to follow fat-tailed (Power law) distributions. What does this mean for training not just the models, but also building Agentic systems?
- AI alignment is obviously a very important area of focus. What does it mean in the enterprise context, where the need is for a much narrower, focused alignment? How much of the alignment can be resolved with system prompts and when would the need for domain specific models come in?

Leave a comment