In enterprise data circles, it is a well-known statistic that less than 30% of companies claim to have been successful in becoming a data driven organization. What is not so easy is to figure out why companies have such a hard time getting actionable insights from data – in my experience consulting with many companies, big and small, the reasons mostly end up converging to two reasons: 1/ There is not enough data 2/ There is not enough compute capacity. Which is not only reductionist, but also misleading. This post all about challenging some of the pre-conceived notions on data management in enterprises. At this point, it is also worthwhile to mention that I work for AWS and conventional wisdom would have it that I subscribe to both of these reasons, but I will lean on the principle of customer obsession, which advocates above everything else, alignment with our customers business goals and not pushing down tooling for the sake of it. Let’s get to it then.
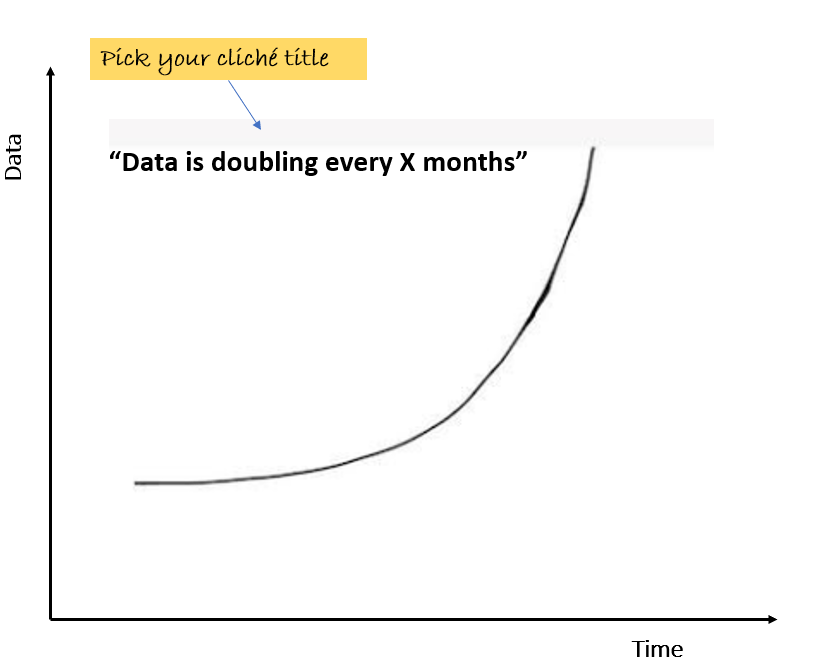
Observation #1: We are obsessing over the wrong data metric
The obligatory opening slide in most CDO (Chief Data Officer) presentations is the exponential growth of data. While that is definitely true of data in the digital universe, the real question for a CDO is: What are the outcomes that the business wants to achieve and to do that, is it really, really necessary to pile up all this data? What are we trying to do with chasing down every possible data in the organization and in the process, reducing the signal-to-noise ratio? In other words, how did data go from being a means to an end in itself?
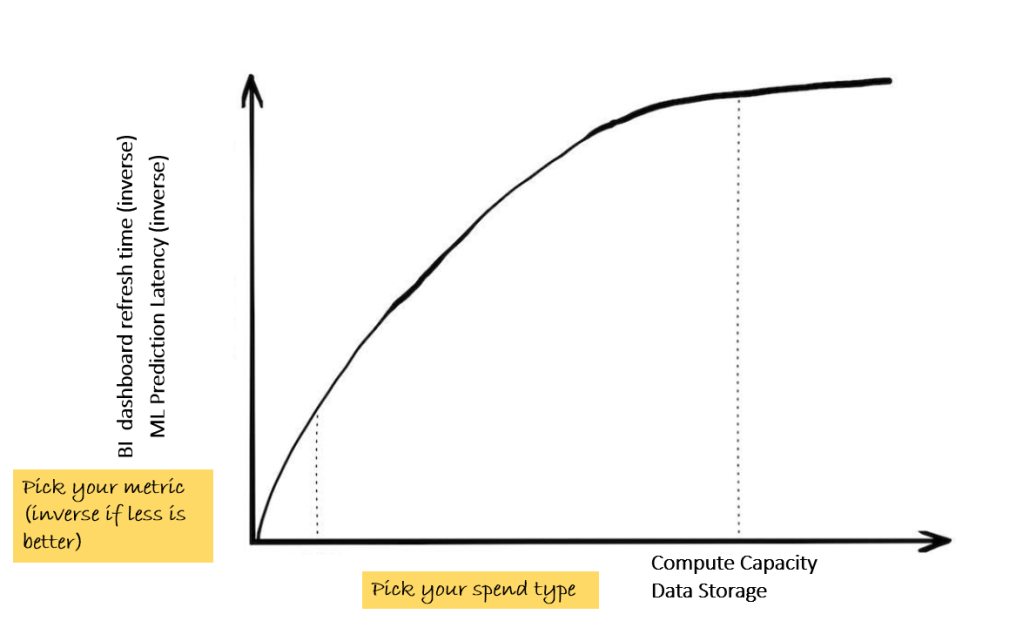
Observation #2: Value from data systems shows a logistic growth behavior
Ask any scientist and they will tell you that information growth in nature is a logistic asymptotic function with complexity. In other words, as complexity in nature grows, all phenomena converge (except of course, viruses but that is not relevant for us here). If the CDO takes a business relevant metric like time taken to refresh a BI dashboard or the latency for a ML inference point to make a prediction (proxies for accelerating time to insights) and plots that against inputs like data volumes or compute capacity, it is likely to look like this. In other words, the incremental value from data and compute continues to diminish with size. This is fundamental to nature and data would be no different.
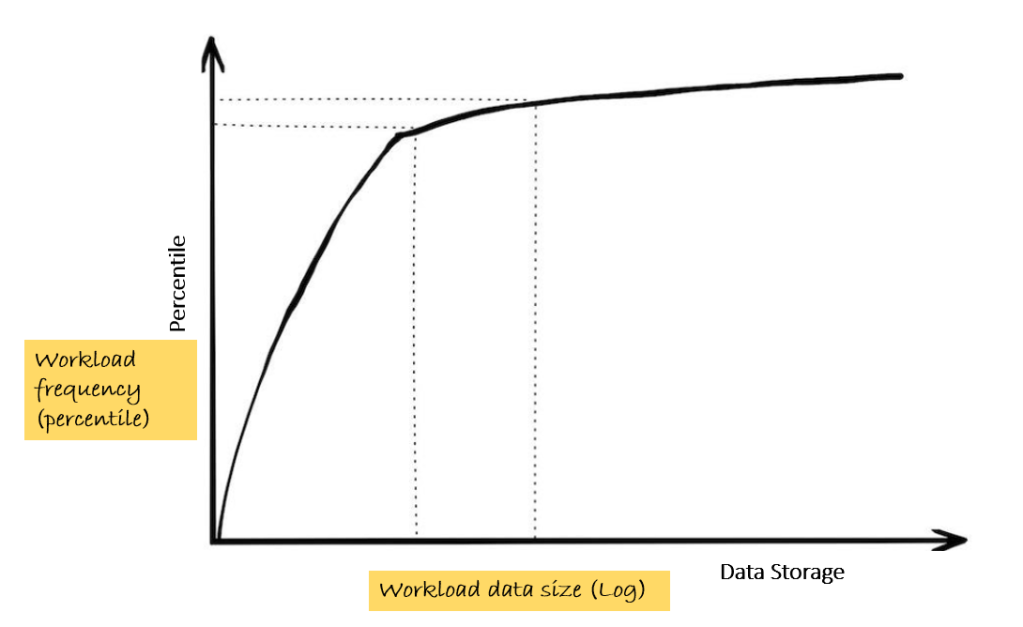
Observation #3: Heavy workloads are infrequent
‘Billions of rows processed on a daily basis at lightning speed’ is more often than not, a myth perpetrated by technology teams, often as an end in itself. While it is true that large workloads continue to grow, they still form a small part of the overall volume of workloads. And in any case, most of these large workloads are scheduled batch jobs (e.g. aggregation of transaction data to compute metrics at a pre-defined time interval; ML algorithms refreshing the predictions triggered by refreshed data at pre-determined frequencies). The way to monitor this is to track the frequency of data processing jobs against the query workload sizes.
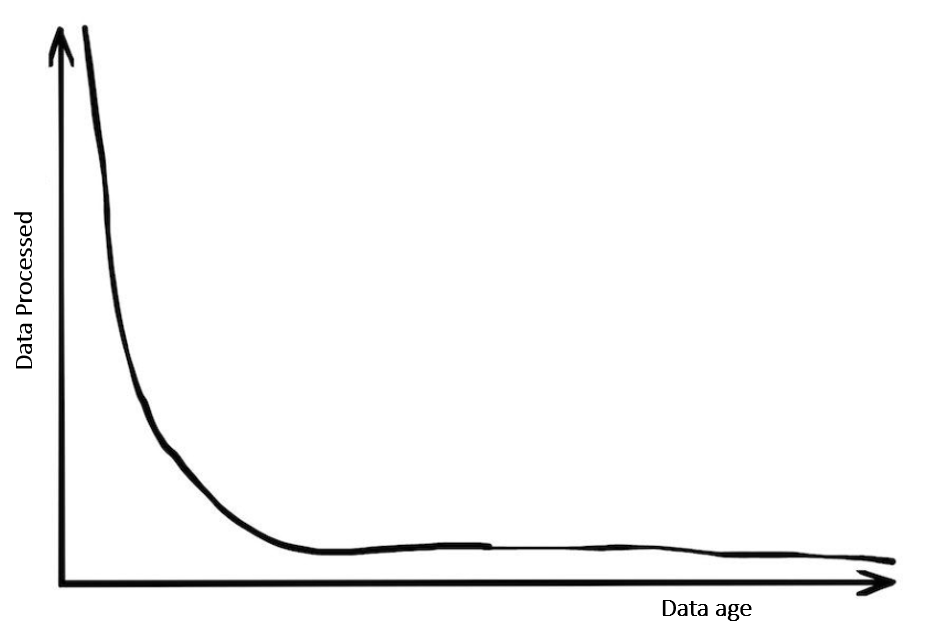
Observation #4: Most data is rarely used
The VP, Data Engineering at a very large, digital customer we work with wanted to test this hypothesis. They looked at the % of the access that data lake users have that is actually used (with a fairly liberal definition of accessed at least once in the last 12 months). And it turned out to be less than 0.2% – i.e. a typical user with access to 1TB of data ended up actually using just under 2GB of that data over a period of 12 months! This does not include large batch processing jobs, but the point is clear: users are literally looking for needles in haystacks. A corollary to this: as data ages, its use falls rapidly, with some exceptions (e.g. audit enquiries)
And hence it follows that: Data is a Liability
The conventional wisdom that drives much of this behavior is that for data, “the cost of keeping data is around than the cost of not having it when you need it or the cost of throwing it away”. If some of the observations above hold true, this encapsulates why companies end up not with clean data lakes, but large, somewhat messy swamps: data exists not because it is needed, but they just haven’t bothered to delete it or most likely, didn’t want to think through the uses of data. In other words, Data is a Liability
So, what do we do?
Talk to any CFO about a balance sheet liability, and they will tell you how important it is to monitor the liabilities and keep asking the hard questions. The same goes for Data: apply the trusted OODA method of thinking about data:
1/ Observe: Define the right metrics to monitor organization data. The 4 observations above is a starting point – define the right metrics and start tracking them. Understand the current state and define a target state that can be measured as OKRs.
2/ Orient: Define governance (access, quality, retention etc.) policies and the underlying tooling to instrument the data activity and map to the metrics.
3/ Decide: Define incremental targets as milestones to the target state and integrate them into the OKRs
4/ Act: Implement data policies (e.g. Fine-Grained Access Controls, Quality score cards, data archival etc.) through the right tools and use that to monitor progress. Rinse and repeat

Leave a comment