Over the last few posts, I had explored the overall idea of how to approach the problem of decision making in a world of ‘tail events’ and insufficient data. And increasingly, it is clear that most Analytics teams in organizations are not very well equipped to navigate this order of complexity. Over the next couple of weeks, I want to explore how it has come to pass that most Analytics teams (or Data Science teams – which is mostly a case of old wine in new bottles) find themselves at sea in this ‘new normal world’. And perhaps it is time to evolve the organizational code on how to build these teams.
How we got here
As they say, it is important to know how we got here before figuring out where to go next. So, a short history of how Analytics has evolved in organizatio. If you walked into a typical Fortune 500 company 25 years ago, you would most likely run into the ‘quants’ in two nooks. First, a small group of statisticians in Market Research working on data trickling in through surveys or focus group studies. The second: Operations Research folks in Supply Chain planning, working on models from scheduling to safety stock/replenishments. Starting in the mid-2000s, you could see things changing – for one, more data started becoming available. Then came the e-commerce explosion, and before you knew the clever boffins from Market Research started putting out some really powerful insights for driving marketing campaigns, engaging with customers et al. And the rest is well-storied: in a short span of less than 10 years, Analytics went from a back-room affair to being labeled as the ‘sexiest job of the 21st century’. The race to scale has led to the ‘factory model’ and when that happens, there is the inevitable push towards standardization and repeatability. Ergo – regression went mainstream. Every prediction problem magically seemed to fit into a supervised learning regression box. And then, Machine Learning came along and vastly expanded the horizon. And all this while, some of the deep problem-solving talent in Supply Chain Operations withered away – mostly because solving operations problems didn’t get the C-suite’s attention compared to marketing and customer insights.

And so, it has come to pass: most data science teams in organizations are staffed with analysts who are usually tasked with shuffling around different algorithms to extract relevant insights from data and integrate the insights into core business processes (aka operationalization of analytics). While this has undoubtedly created value – what seems to have been diluted in the process is problem solving capability: the ability to take on tricky problems and explore a wide variety of solution strategies to come out with actionable insights. As we now stumble into this ‘new normal’ of increased uncertainty, a different order of complexity, I believe the time has come for organizations to augment the core Analytics talent.
The Uncertain and Complex world we live in
Let’ start with a mental map of the problem-data space and how that is changing in this new world.
The Problem continuum
A few weeks back, I had discussed the idea of wicked and kind environments. This is a good framework to think of the business problems as well.
Kind problems: These problems are well-defined and bounded i.e.:
- The problem can be articulated in clear, unambiguous terms
- There is a clear feedback loop because the solution can track and report any changes in the problem. This enables the owner to monitor and tweak the solution as the problem evolves over time
Wicked problems: These are the knotty problems with little clarity and often open-ended:
- The problem is often slippery and takes several solution iterations before you can settle down on a reasonable solution
- The feedback loop is not very clear – which makes it hard for the owner to understand the effectiveness of the solution
The Data continuum
We will use data in its broadest sense – this is the collection of all ‘signals’ generated in the context of the problem. These range from transactional (e.g. loan installment payments) to behavioral (e.g. response to payment reminders; switching of payment channels etc.). The two book-ends of the data space:
‘Good’ data: Data that leads to solutions using well understood, repeatable solution strategies (i.e. factory mindset):
- High signal to noise ratio
- Well-understood, stable distributions
- Adheres to the ‘law of large numbers’: i.e. converges to the population characteristics
‘Ugly’ data: This is the opposite, data that makes the solution process arduous and often frustrating:
- Low signal to noise ratio
- Fat-tail distributions
- Unstable and takes a much larger sample size to fully understand the distribution
Two important points here:
- We all know that problems are not ‘static’ entities but are changing all the time
- It follows that problems can move (sometime with alarming speed) between kind and wicked states
And with that, we can attempt to define classes of solution strategies that are driven from the problem-data context. A simple example of a customer loan default prediction model also serves to illustrate the example
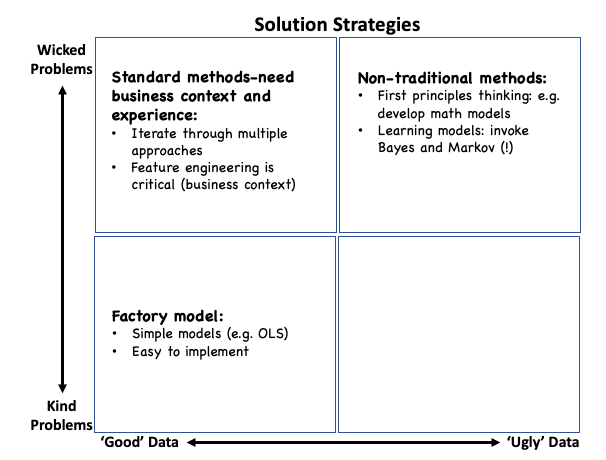
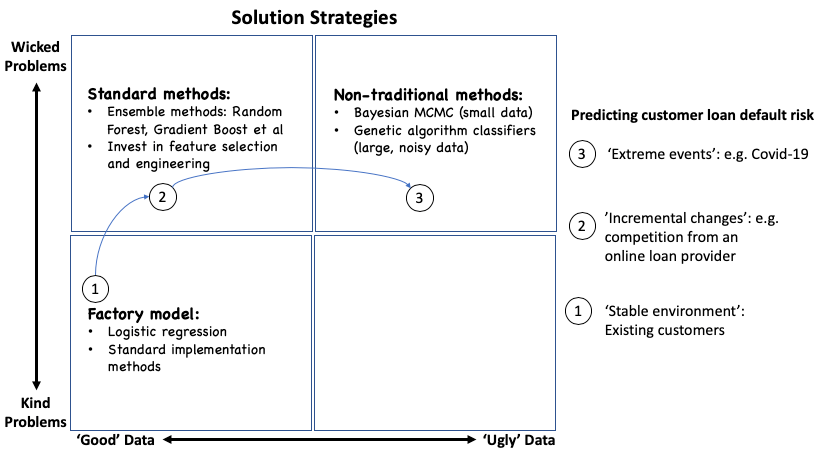
So, what does this mean?
Most CDOs have begun to see this emergent phenomenon – the rapid ‘shifting’ of problems. And this will continue to be the case for some time to come. After several iterations, most data science teams have built the technology and talent capacity to tackle problems in stable environments and at best, incremental changes. However, true competitive advantage will lie in the capability to solve the truly wicked problems within the constraints of ‘ugly’ data.
Once we accept that there is an absolute necessity to invest in an elite team of ‘Navy Seal’ problem solvers, the question is: how do you go about building this team? What type of talent should we look at? For that, we will turn to different fields where problem solving is a core skill for inspiration: physics and computational genetics. If you think that is too far out, look no further than where the Wall Street firms went to for talent when they started to build the quant divisions in the late 1990s. Topic for next week.
Credits:
- My all-time favorite comic series by Randall Munroe: http://www.xkcd.com. And while you are there, do check out the what-if section – amazing stuff for the mildly curious
- On kind and wicked environments: https://pdfs.semanticscholar.org/5c5d/33b858eaf38f6a14b3f042202f1f44e04326.pdf
- A general inspiration: https://davidepstein.com/the-range/ although do note that when he says ‘generalists’ he really means someone who is deeply grounded in a specific area but then has the ability to switch domains as well

Leave a comment