In 2020, Gartner identified Composability as a key factor to be resilient and agile in an uncertain and rapidly changing environment. Fast forward to 2022 and as most companies are bracing down an economic slowdown, it is becoming important for CIOs and IT leaders to accelerate the adoption of technologies that help business functions to: 1/Sense or discover when to respond to change. 2/ Drive a rapid, data-driven response to the change. For this to be possible, users that are not technology professionals (i.e. business users) should be able to build and deploy technology products and services. Another study by Gartner says that by 2024, 80% of net new technology products and services will be built by non-technology professionals. In other words, we should expect to see a huge surge in low-code development technologies.
Which is where Software 2.0 comes in, and the question is this: is the idea of Software 2.0 limited to a limited set of AI centric applications (autonomous driving, image recognition et al) or is it a broader trend that the enterprise world should start thinking about in the technology landscape? I believe the answer is Yes.
What is Software 2.0
Here’s the definition from a blogpost by Andrej Karpathy: In Software 1.0, human-engineered source code is compiled into a binary that does useful work. In Software 2.0 most often the source code comprises 1) the dataset that defines the desirable behavior and 2) the neural net architecture that gives the rough skeleton of the code, but with many details (the weights) to be filled in.
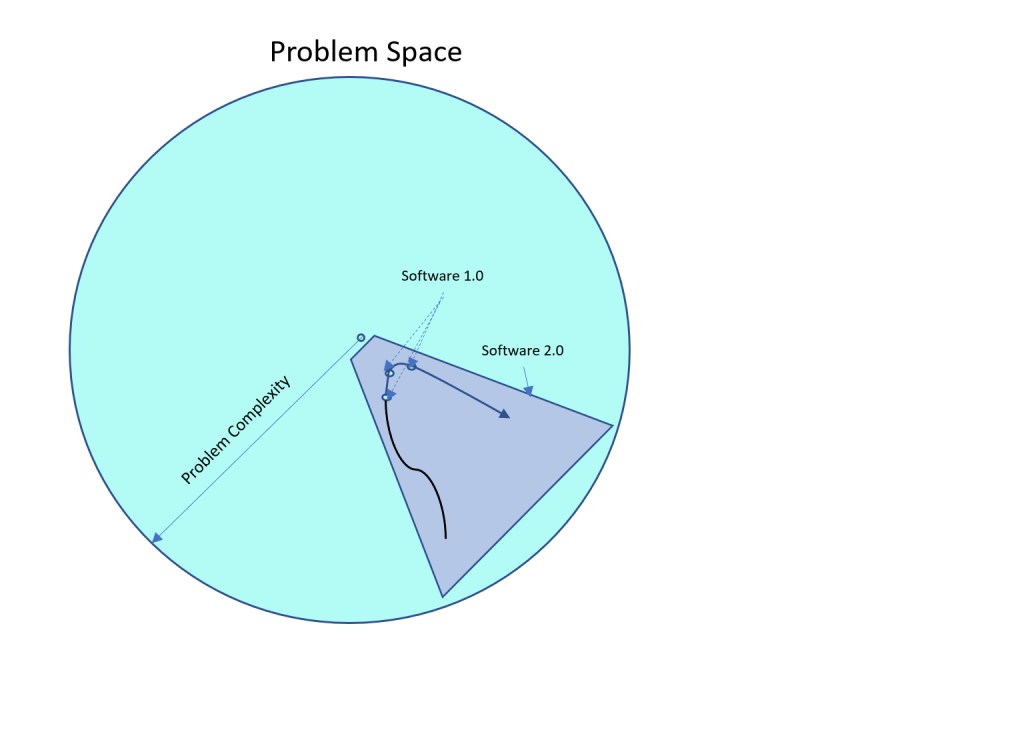
The shift from Software 1.0 to Software 2.0 has been going on for some time now. Here’s an example: A Supply Chain manager in a manufacturing company, tasked with managing safety stocks at various points in the supply chain, has long relied on software that recommend target safety stocks at each node in the supply chain.
Software 1.0: A majority of the existing solutions use a well-defined formula  This formula is converted into code written in Java, C++ etc. using a series of explicit instructions. Underlying this is an assumption that this explicit formula captures the entire problem space of safety stocks. Which works well most of the time, but then falls apart in several edge-cases (e.g. during product launches, during extreme events, products with long-tail demand. The list goes on). Software 1.0 forces simplifying assumptions (e.g. in this case, demand follows a normal distribution) with an accepted trade-off that relies on human judgment to intervene to adjust the outputs on an as-needed basis.
This formula is converted into code written in Java, C++ etc. using a series of explicit instructions. Underlying this is an assumption that this explicit formula captures the entire problem space of safety stocks. Which works well most of the time, but then falls apart in several edge-cases (e.g. during product launches, during extreme events, products with long-tail demand. The list goes on). Software 1.0 forces simplifying assumptions (e.g. in this case, demand follows a normal distribution) with an accepted trade-off that relies on human judgment to intervene to adjust the outputs on an as-needed basis.
Software 2.0: The approach here is to specify a goal (in this case, target service levels and costs), an overall ‘architecture’ that ‘searches the space’ (e.g. a simulation engine that generates scenarios based on past data or a neural net that learns from ‘experience’ with humans teaching) and learns through a feedback system of rewards/penalties. This represents a fundamental shift from Software 1.0 in two profound ways:
1/ There is no a priori assumption of a deterministic formula, giving it a better chance of adapting to different scenarios.
2/ There is an element of continuous learning, with a combination of training with historical data and an ongoing feedback loop
What has made this possible?
1/ It is apparent that for Software 2.0 to do better than Software 1.0, you will need lots of data (to store all the historical data) and compute power (to simulate scenarios or refine the weights on an ongoing basis). The cloud is driving the marginal costs of compute and storage down to a point that is making Software 2.0 possible outside the rarified worlds of the likes of DeepMind.
2/ Uncertainty continues to grow over time and that continues to reduce the accuracy of deterministic solutions developed in a Software 1.0 paradigm. Instead, organizations are increasingly being forced to look for probabilistic solutions that start with historical data and continue to learn over time. See my earlier posts on this topic
What are the barriers to adoption?
Software 2.0 is an obvious fit where: 1/There is access to data (e.g. recognizing cat images; playing chess, Go etc.) 2/ The decision and error costs are low enough to allow for learning at scale. Both of these conditions are more often than not, untrue in enterprise situations. Back to our inventory safety stock example: access to historical data is limited to the enterprise data and as any inventory manager will tell you, the cost of a stock out is often very large and in any case, experimentation for safety stock levels is not possible in most circumstances.
However, it is important to embrace the mindset behind Software 2.0: begin by acknowledging that it is no longer good enough to rely on simplistic solutions that were developed in a world constrained by limited data and expensive compute power. And with these no longer being constraints, it is time to embrace a Software 2.0 mindset: be greedy about capturing data, exploit compute capacity to build solutions using the vast (and ever increasing) corpus of Machine Learning models that can be trained on data, continuously learn and improve over time with feedback.
Footnote: In case of the safety stock problem, the solution was to challenge the fundamental assumption that the demand follows a normal distribution in all cases. Instead, identify the probability distribution function under different scenarios (e.g. launch, end-of-life etc.) based on historical data. For each such case, build a simulation engine that would try to seek a target safety stock that would optimize the goal (i.e. Target Service Level). And use the actual service levels to further attach positive/negative ranks and further ‘teach’ the simulation engine. Not quite Software 2.0, but the underlying principles were very much the motivation that led to an improvement in outcomes.
Next, will cover one of the key design features of Software 2.0 – a multi-competency architecture. There is some very interesting work going on in Biology that can inspire how to design and build AI systems as a hierarchical network of agents that work towards a common collective outcome. Here’s a fascinating interview on the topic of goal-seeking behavior by self-organizing agents.
Links
- Gartner studies:
- https://www.gartner.com/en/newsroom/press-releases/2020-10-19-gartner-says-organizations-should-strive-for-composability-to-be-resilient-and-agile-during-uncertainty
- https://www.gartner.com/en/newsroom/press-releases/2021-06-10-gartner-says-the-majority-of-technology-products-and-services-will-be-built-by-professionals-outside-of-it-by-2024
- Fascinating podcast by Lex Fridman – it is brilliant in the range of topics, the sheer intellectual abilities of Lex Fridman and his guests :https://lexfridman.com/podcast/
- Software 2.0 blogpost by Andrej Karpathy: https://karpathy.medium.com/software-2-0-a64152b37c
- Biology and multi-scale intelligence: Implications for AI/Machine learning approaches: https://www.goodai.com/a-conversation-with-michael-levin/

Leave a comment