Here’s a thought experiment: Fred and Bay want to run a coin toss experiment. They want to make sure that the coin is completely unbiased – so they go to the US Mint and get a quarter that has passed all its tests (i.e. there is no manufacturing defect[1]); toss the coin 100 times. They record 55 heads and 45 tails. Now the question is: what would be the probability of coming up with heads on the 101st toss?
Fred: Given our observations so far, it should be 55%. That is the only observable truth that we have – we cannot take any prior assumptions about the coin that US mint told us.
Bay: I disagree – it should be 50%. Based on our prior knowledge of the coins from the US mint, we believe that the coin is a fair coin and our observations are not enough for me to ‘update’ that belief.
The point is not really whether Fred or Bay were right – there is a more fundamental issue at play here: Do you make decisions by keeping your ‘apriori knowledge’ aside and only on the basis of observations? Or should you start with a base assumption and keep on adjusting on the basis of your observations? Turns out that this is not a philosophical question but has practical ramifications – and I will try to chip away at what this means in today’s post and what this means to our decision-making models[2].
In the last post, I had talked about trying to build a model for an early warning system based on limited data on extreme events. Take a look at the unemployment claims in April 2020 – an extreme event if there ever was one. Almost every bank saw just about every credit product slammed with a massive spike in defaults. While almost everyone expected it, few would have bothered to update their customer risk models – and for good reason. There is no data out there to train your models.
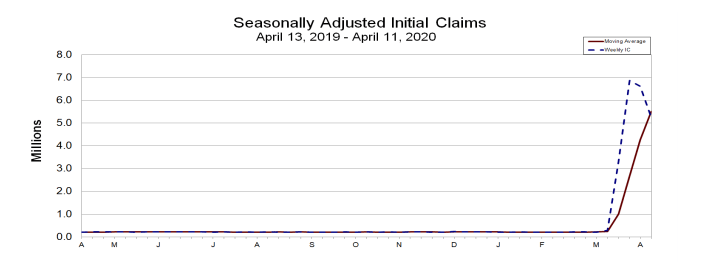
Fig: 1 Unemployment claims: published by Department of Labor, US Govt.
The really, really important (and hugely material) question is: how many such observations would the banks need to be able to adjust their models? And more generally, just about every decision maker is going through a similar gut-wrenching situation: As we navigate through this ‘new normal’, how do we rebuild our prediction models?
Let’s take the case of the customer ‘propensity to default’ on a mortgage loan installment. In most cases, this has been solved using the frequentist approach: probabilistic models that are trained on past data. While actual implementations have grown to be very sophisticated, the underlying frequentist principle continues to be the same: most data science models are built on the assumption that the underlying distribution of data does not change over time. This has profound implications: in data alone, we trust (with confidence intervals, of course); we do not require prior knowledge and so on. This sounds like a simplifying assumption – because it is in most normal circumstances. Except when circumstances are not normal – which brings us to today. Take a look at the US unemployment claims for the last 12 months. For 11 months, the above principle has worked very well, and now all of a sudden, this assumption is the Achilles heel for pretty much every prediction model out there.
What does this mean?
As usual, it is useful to visualize the problem. Here is a simplistic representation – the chart on the left represents data for a set of defaulters where the ‘state change’ (from no default to default) was recorded in April, 2020. The standard approach would be to ‘fit’ a probabilistic model (in this example, a logistic regression model). However, as we can see there are multiple curves that can fit – and since we are working with a small dataset (one month of outlier behavior without any precedent), it is difficult to pick the best curve fit. And so, the data scientist would have to qualify her recommendation with, yes – the ‘confidence interval’. And this has been the narrative all these years – and so long as we were working with computational constraints, this was just about the only alternative. The question we want to ask is: can we improve on this decision system?
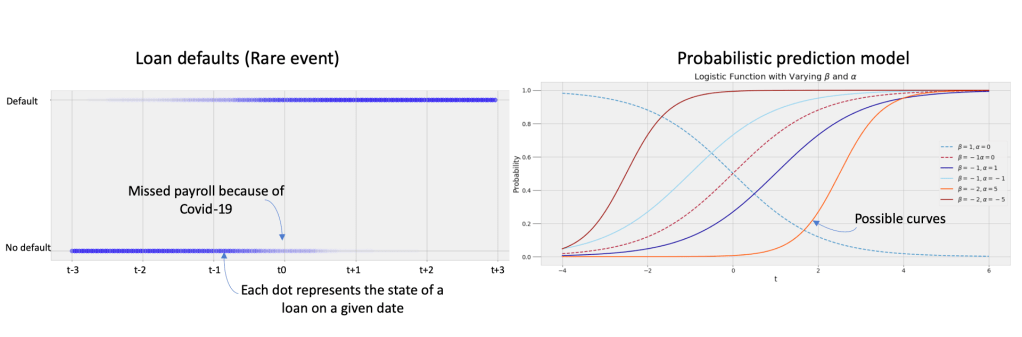
Should we give the Bayesians a chance?
The Bayesians would look at the same problem with a fundamentally different lens. Remember these are the ‘apriori’ guys – i.e. start with a ‘subjective prior’ constructed based on intuitive knowledge of the situation. So, their starting hypothesis would be to take a ‘guess’ at the behavior of the defaulters – in case of our logistic model, that would be encapsulated in the parameters (alpha and beta of the logistic function). With this, the Bayesians have opened up a possibility for us:
- Can we settle on a starting ‘definition’ of the underlying defaulter behavior? In other words, can we start with an initial hypothesis of the probability distribution for the defaulters?
- Can we ‘explore’ different behavior patterns for the defaulters? In other words, can we try out different values of the parameters?
Enter the next piece in our puzzle: Simulation[3]. Here is roughly how to make this work:
- Go back into history and study how credit customers have responded to large, sudden exogenous shocks. And there are a handful to learn from – just in the last 20 years, two large recessions (the 2000 crash, the great 2008 recession); multiple localized ‘black swan’ events (e.g. Hurricane Sandy, Katrina and so on). Crunch through these datasets and arrive at an initial hypothesis for the underlying distribution (i.e. the parameters – alpha and beta)
- Simulate different values for the parameters
- For each value, test how well it fits to your limited set of observations (April data).
- Repeat 2&3 until you gone through a number of iterations or you have converged on an acceptable level of accuracy
This does have the potential to give us a better solution than the earlier alternative of blindly guessing our way out. We will explore Simulation (specifically, Monte Carlo Markov Chains or MCMC) and Bayesian inference: and the opportunity it provides to better navigate the world of extreme events and small data. As someone said, “the value is not in big data – it is actually the ability to make better decisions faster with small data”. Never has this been truer in the maelstrom of extreme events that we are going through right now on a global scale.
Footnotes
[1] Some trivia: In 2020, The US manufactured over 1 billion quarters, and according to their website, they have a defect rate of 0.7%: so the odds that you will get a fair coin is high, you get the point).
[2] Bayesians vs Frequentists: And Fred represents Frequentists while Bay represents the Bayesians (now you get why I picked those names!) – and if you are interested in some good old-fashioned academic rivalry that can get downright nasty and verbally violent on the internet – this is one of the more colorful ones.
[3] Simulation: Topic for the next post – and for that, we will travel over to Russia and meet yet another mathematician whose ideas are making a big comeback: Markov. He was quite a character – more on that later.
